As far as buzzwords go, serverless is one of the most widely used when it comes to software development and infrastructure management. All that talks about using FaaS (function as service) like AWS Lambda, and NoSQL databases like Dynamodb can be exciting at first and become mind-boggling real fast.
Most of us remember the days when we could put together the code in an application, compile it and deploy it on a server, all so predictable and all so straightforward. Now, we have to deal with the fact that anything can fail at any time.
Going cloud-native as a community, when we removed the single point of failures from our lives, we introduced many points of failures. Any team that has worked on serverless long enough and hard enough knows this to be true.
So, this article is not your ‘yet another blog post about how serverless is the silver bullet for anything between writing code to world peace’ but rather focuses on how to do it right while making your team’s software development and management experience better.
Scalability, accountability, simplicity & consensus are the guiding principles at the foundation of serverless development/deployment at WealthDesk. These seem like your typical catch-phrases at first, but when applied to individual parts of our software development processes, we start seeing some sensible approaches to doing things. But first, some basics!
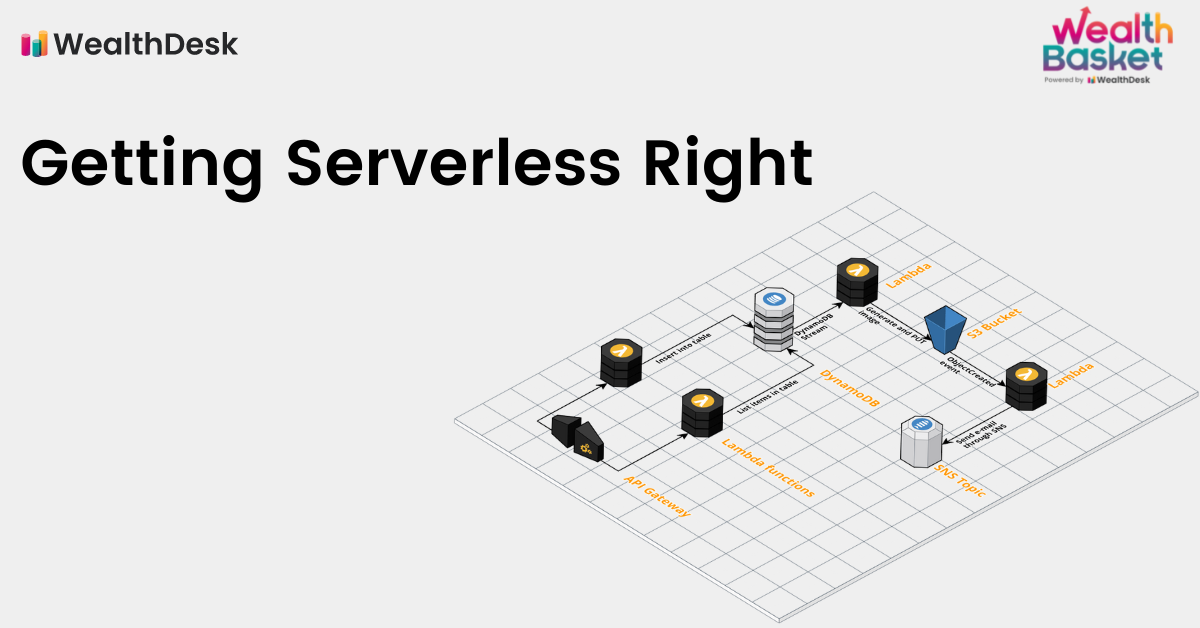
Serverless functions (aka Lambdas)
Lambda functions are like sheep. One goes astray, another follows it, and then another and so on, and soon you have your whole herd going haywire. In technical terms, translate this as – Lambdas that belong together must stick together. They are definitely the building blocks of a good serverless application but think about getting the best of the microservice patterns and functions. Your code may be deployed as individual lambda functions, but it will be a lot easier to manage if you write it like a microservice. Here are some pretty basic things to keep in mind:
- Put the relevant lambdas together
- Use tags heavily to identify microservices.
- Use consistent environment variables. Seriously, this becomes a big problem very fast.
Writing a new repository makes sense for a microservice, especially if you are starting a new project. Write common libraries for error handling, common response classes, etc. They come in handy for you and your fellow devs.
Organizing your JIRA
Wait, this isn’t one of those gotcha moments about how doing JIRA correct will solve all your problems magically. But it’s worth noting that teams often treat Epics as big boxes containing smaller boxes of stories, which are big boxes for tasks. Treat an Epic to a product what a microservice is to engineering.
Managing repositories
Enforce consistent programming language versions from day one. If you see a different version of the language used anywhere that does not warrant an exception, shoot it down. Remember what I said about sheep.
Start from your repository management software, e.g., bitbucket instead of the IDE. It’s less cluttered and gives you a free .gitignore file.
Enforce consistent naming conventions and folder management rules; remember the sheep. Chaos is the enemy, don’t let it in, even while naming your files.
Consistent dependency management, e.g., our python projects have a requirement.txt file that lists all dependencies. Developers agree that the pipelines will build code basis strict dependency declarations. However, use only those dependencies necessary for your microservice’s functioning. A common mistake is to include everything everywhere or most things everywhere. You think you may need it later; you won’t.
The serverless way is to ensure the bare minimum – every single time. Also, see if any non-library solution exists before you import it. More often than not, you will find that to be the case. Don’t import an entire library to use one functionality; copy-paste it and make it part of your own little kit of libraries.
If there are multiple functionalities in a single microservice, turning them into directories is advisable. Each functional directory should, in turn put its lambdas in the sub-directories that look something like this :
- APIs: Lambda functions that respond to APIs, although they may respond to other lambdas too.
- Triggers: For triggers on dynamodb, cloudwatch events (cron) or any other service/stream/event-based invocation.
- Services: if multiple directories or files use services, put them here. Use extreme prejudice before turning something into service. It may be an unwanted abstraction.
- Utils: Sometimes, you may want to perform some tasks locally as part of go-live, needing some initial code to run if something breaks down or needs to be changed. Write that here. Functions and classes in utils should be invoked one time. Although, if your utils outnumber your lambdas, maybe you are doing something wrong
How to structure your code
A well-structured code is crucial from a readability and maintainability standpoint. Here’s something that can help you structure it better:
- Favor code duplication over over-abstraction. It may sound counter-intuitive, but as your project and the platform evolves, this will help you move the code between microservices.
- There is nothing wrong with a shared lambda, i.e., one lambda responds to multiple actions. However, don’t club read and write side, though. Terrible idea!
- While favoring duplication, also write less code. Think about how you can cut things shorter and shorter until you can’t. True beauty lies somewhere smack dab in the middle.
- The best code is the one that never gets written, but you should avoid writing direct AWS service proxies. They are the perfect weapon of vendor lock-in and are crazy hard to manage. Sorry AWS, we love you, but we love freedom more.
- Most engineers write Lambda functions as APIs, nope. They are called lambda “functions” for a reason. There’s a mantra for this- JSON goes in, JSON comes out. Any transformation towards the input JSON should be handled at the API gateway.
- For Python folks out there, stubs are pretty decent. Especially when you are using boto3.
- Use smart commits and make your life simpler.
- Use SAM and make your dev testing simple. There are some secret pathways to explore that will make life amazing. Dev testing is super simple through SAM.
How to structure APIs
At WealthDesk, we follow one API per microservice and one path per stakeholder approach. The APIs themselves are managed inside the same Cloud Formation Templates used for other resources.
Here are some advantages of doing this
- Custom domains are easier to manage
- A meaningful number of endpoints that are closely related in a single API gateway be
- Easier UI integration
- Decoupling microservices while having a single path published per microservice at the other end.
One thing worth noting about API Gateway on AWS is to leverage body transformation and mapping templates to make your API gateway talk meaningfully with your lambda functions.
Amazon API Gateway. Lambda proxies look very lucrative at first, but they counter the serverless way, and everything eventually becomes tightly coupled. Think as if you are making the actual JSON that will get passed on to your lambda and the response your lambda generates as JSON – because that’s what you are doing in data transformation.
Final thoughts
We observed a few patterns emerge around data persistence and API formatting. Here is an example of this.
- Write side APIs → lambda → Dynamodb
- Dynamodb trigger → Lambda → Redis
- Read side APIs ← Lambda ← Redis
This is a typical Command–query separation scenario; others are too. The basic idea is that lambdas pretty much start writing themselves once you identify these patterns.
Know that you will work on a limited number of services, so your boilerplate code will look pretty similar. That leads to the serious temptation of over-abstraction. Avoid it like the plague.
Most projects fail when the engineering team lacks clarity on how the microservice will look in the end. That is what leads to most of the problems around serverless. You may not know your entire project’s scope, but if you don’t know the last detail about a given microservice, you have to think things through again.
Remember, the world sees your application as a monolith, you see your application as a collection of microservices, and AWS must see them as decoupled pieces held together. Once you start thinking with this approach, you will have very little difficulty wielding this powerful weapon in the modern-day computing arsenal that we call the cloud.